I recently found a rather lengthy variable name in some code, and mentioned it to a friend. It looked like this:
private final static double THREE_LETTER_ACRONYM_RATIO_FOR_THING = 4.321;
This was used about six times in several functions. This lengthy variable name, which annoyingly followed the Java standard of using capital letters for constant values (a blatant misunderstanding of why C preprocessor macros are capitalized is probably why this is used in Java), also spelled out a common TLA1.
My friend, however, knew my penchant for short variable names like:
FooBar fb; // instead of fooBar or even worse, fooBarForWidget
So, he said that he liked the long name and would have preferred it to some incomprehensible shortening of it. With modern IDEs, why must we remember cryptic shortening of a name? I remembered Zipf's law, and decided to spin it like this, "If you fail to account for Zipf's law, your code will be hard to read due to its constant repetition of contextual information."
What I meant was essentially this: if you're working with, say an image, you have a few different ways to name the height and width variables you're using. You could use "currentImageWidth" or maybe "imageWidth" if you're only working with one image, which could even be shortened to "width" or, gasp, "w". What is the difference between these four variable names? How much contextual information you are embedding within the variable name, rather than relying on the reader to remember that we are talking about images.
The use of a particular one of these four then depends on a few things:
- How likely is it that the reader is aware we are talking about images?
- Are we using only one image or are we dealing with multiple images?
- How likely is it that there is only one width that the reader thinks we are talking about? (Perhaps there are other widths as well, such as a page width.)
- How likely is it that the reader would associate the letter "w" with an image width?
- Would the shortening violate a common idiom, such as using "i" or "j" for something other than a loop counter?
Depending on the likelihood of these questions, one would pick the correct variable name. My friend and I agreed that this is indeed the heart of the issue, but couldn't agree on this particular circumstance. If this was the Internet, we would merely start raising our voices and start shouting nonsense. I decided to go a different route. I found a paper on the topic.
Background
But first, some background. What exactly is Zipf's law and why did I cite it?
Let's say you count the number of times a word is used in a block of text. Now, sort by the count of each word, such that the most common word comes first. What will the distribution of numbers look like? A Zipf distribution, of course.
But what does that look like? Zipf's law appears linear if you plot the count and the rank on a log-log graph because it is a Power law distribution. This is the same type of function as the Pareto principle and inverse square laws like gravity. A power law distribution is a density function defined as:
$$ p(x) \propto x^{-\alpha} $$
Zipf's law is the special case where $\alpha \approx 1$. Here is a helpful plot from Wikipedia of Zipf's law at four scaling factors:

You can generalize Zipf's law into the Zipf-Mandelbrot law if that's your fancy too. But what does Zipf's law mean in a more general sense?
It means that speakers tend to choose words that are more readly available to them. It's likely part of the same memory recall that the availability heuristic is based off of. This, in turn, makes listeners require that speakers embed more information in their messages to supply additional contextual information.
Words that are used more frequently almost certainly have less specific meanings than words that are used less frequently. And what of variable names? I think that if you violate Zipf's law in the length of your variable or function or class names - that is, their frequency exceeds their length - your readers will not thank you, but instead have a harder time reading your code.
Least effort and the origins of scaling in human language
Knowing Zipf's law I set out to find a modern paper that discussed its implications with regards to how much effort the reader and writer of language must put forth. Knowing Guido's rule that, "code is read much more often than it is written" it is important for writers to exert more effort than readers, so that their extra effort is amortized over many readers.
I found a nice paper from PNAS, called, "Least effort and the origins of scaling in human language" by Ramon Ferrer i Cancho and Ricard V. Solé3. Let's read it together. The right place to start is the abstract to see if it is what we want. Make sure to grab the paper and follow along. Even better is if you read the section before I discuss it.
The Abstract and Introduction
Quote from the abstract:
"In this article, the early hypothesis of Zipf of a principle of least effort for explaining the law is shown to be sound. Simultaneous minimization in the effort of both hearer and speaker is formalized with a simple optimization process operating on a binary matrix of signal-object associations. Zipf's law is found in the transition between referentially useless systems and indexical reference systems. Our finding strongly suggests that Zipf's law is a hallmark of symbolic reference and not a meaningless feature."
So, Zipf's law is mapped to a concept of least effort through a formalization of a process. They do this through a binary matrix - us programmers know all about that, so that's alright - of signal-object associations. So we're going to be mapping signals (symbols) and objects through a matrix. Zipf's law is apparently a transition between two types of communications systems that suck, probably ones associated with full effort on either the speaker or the hearer's part. So in communication systems (and hopefully computer programs apply) Zipf's law is a fundamental aspect. Hopefully we can apply it to variable name-length.
This sounds exactly like what we want, so let's continue.
The introduction discusses the origin of human language and related research. The authors also lay out some of the foundations for the model they will be using. Necessarily, they say that the more meanings for a symbol or word, the more effort the reader needs to expend to decode the word. You can imagine how much more difficult reading a program would be if it was composed only of a few variable names, and reused them all over the place.
However, Zipf's law also states that speakers or writers will tend to choose the most frequent and most ambiguous words. There seems to be a conflict between ease of speaking (choose highly available words) and ease of listening (listen to unambiguous words).
The Model
Now the authors seek to take what they're saying out of the realm of hand waving and into something more concrete: a mathematical model. In the paper they start from symbols and objects and work towards a cost function, but I think it's slightly easier to work the other way around.
We need a way to represent cost of both the hearer and the speaker. Naturally it makes sense that the more effort the hearer needs to expend, the less effort the speaker needs to expend and vice versa. So we can write the cost function, $Ω$, this way, where $E_h$ is the effort spent by the hearer, and $E_s$ is the effort spent by the speaker:
$$ \Omega(\lambda) = \lambda E_h + (1 - \lambda) E_s $$
Since $\Omega(\lambda)$ is a cost function, it stands to reason that we want to lower it. The input to this function, $\lambda$, is merely the weighting between hearer and speaker.
Shannon Entropy
Sounds good, but how can we represent $E_h$ and $E_s$? One way is through the Shannon entropy of a message, which is represented as the expected value of the amount of information in a message:
$$ H(X) = E(I(X)) $$
Do you remember expected value of a random variable? Given a set of outcomes and their probabilties, the expected value is the sum of values times their probability. In the case of all items having equal probability, it reduces to a simple average.
What is $I$? This is the self-information of a random variable $X$. What's that? Well, the information content of a message is the number of bits it needs to represent it; the message 0101 takes four bits to represent. Is that the self-information? Well, it depends on the possible messages that can be communicated.
Say you have this program:
#include <stdio.h> int main(void) { printf("0101\n"); return 0; }
How many different messages can this program give you? Just one. So, how much information is this program telling you? Nothing, it always gives you the same message, 0101. It doesn't tell you anything, and thus conveys no information.
However, if the messages could change, they can convey information. The more unlikely the messages, the more information they contain2.
If each bit has a 50% probability of occuring, the self-information of getting any message other than 0101 (of four binary digits) is:
$$ I(b_i) = - \log (b_i) = - \log_2 ( \frac{ 4^2 - 1}{4^2} ) \approx 0.093 \text{bits}$$
Not very much information because getting any other message is very likely. If all bits are equally likely, though, the information content of 0101 becomes $-\log_2 (1 / 16) = 4$, an expected result.
Put simply, the Shannon entropy, (the function $H(X)$), is the expected information content of a random message $X$. The function $H(X)$ can also be measured in bits.
This can be rewritten in this more useful way, using the normal notation for Shannon entropy, which is the way the authors used in the paper:
$$ H_n(s_i) = - \sum_{i=1}^n p(s_i) \log_n p(s_i) $$
The function $p(s_i)$ represents the probability of symbol $s_i$ being used, like before. This equation works well for the speaker, and is a good candidate for $E_s$. It says this: the effort level of the speaker is the sum of self-information of each symbol and its likelihood.
If all symbols are equally likely, then $H$ tends towards one, the maximum effort level for the speaker. Obviously contextual hints to lower some symbols' likelihood will be necessary to lower speaker costs.
Object matrices and bats
But what are $s_i$ and $n$? Beginning the section on the model, the authors define an n-by-m matrix, call it $\mathbf{A}$, which translates n symbols (words) into m reference objects.
A symbol, such as the word "baseball", would map to an actual baseball in the room in which you are speaking. Actually it needn't be a physical baseball, but could reference a concept or be a metaphor.
It is also possible to have a symbol reference multiple objects (such as "bat" matching both a baseball bat and the animal) and for multiple symbols to match the same object (synonyms).
The set of symbols is denoted $\mathcal{S}$ and the set of reference objects is denoted $\mathcal{R}$.
But what about the hearer?
The same function doesn't work for the hearer, though. Since they are not choosing the words, they cannot describe their effort function in exactly the same way. We need a way to say: how much effort does the hearer expend when they hear a given symbol $s_i$? We need the conditional version of the speaker's effort function.
The authors provide this logical extension:
$$ H_m( \mathcal{R} | s_i ) = - \sum_{j=1}^m p(r_j | s_i) \log_m p(r_j | s_i) $$
If you're not familiar with the notation this is conditional probability notation applied to the effort function. It reads, the effort level of the listener decoding a symbol $s_i$ with set of reference objects denoted by $\mathcal{R}$, is the expected information content of a decoded message. Decoded, because the reference object $r_j$ depends on $s_i$, the symbol in question.
Given what we know about $\mathcal{R}$ and $\mathcal{S}$, how can we describe $p(r_j | s_i)$?
To simplify things, the authors define all reference objects as equally likely, that is $p(r_j) = 1/m$, where $m$ is the size (cardinality) of $\mathcal{R}$. But what should $p(s_i)$ be?
Well, the probability of a symbol $s_i$ is the probability of that symbol appearing associated with all reference objects it maps to. Simple enough. But wait, we actually haven't finished with $H_m$. We have the probability effort level given a particular symbol, but we need the effort level for all symbols. We can use conditional entropy to achieve this. I believe this formula (8 in the paper) has a typo. It should be the following:
$$ H_m( \mathcal{R} | \mathcal{S} ) = \sum_{i=1}^n p(s_i) H_m (\mathcal{R} | s_i) $$
They used the joint probability instead of the conditional probability. If you use the joint probability, this function will be off by $H_m(\mathcal{R})$ by the chain rule. Regardless, we now have candidates for $E_h$ and $E_s$, namely $H_m(\mathcal{R} | \mathcal{S})$ and $H_n(\mathcal{S})$.
$$ \Omega(\lambda) = \lambda H_m(\mathcal{R} | \mathcal{S}) + (1 - \lambda) H_n(\mathcal{S}) $$
So what this says, is that the cost of speaking is weighted by $\lambda$, the higher it is, the more work the hearer needs to do. The lower it is, the more work the speaker needs to do. This is also dependent on the size of $\mathcal{S}$ and its relationship to $\mathcal{R}$, which the authors explore more fully in the next section.
Methods and Results
How do you find the minimum of such a function? I don't know of any analytical methods. The authors do something pretty simple. They start with the matrix $\mathbf{A}$, and then compute the cost function $\Omega(\mathbf{A})$, and check if this is the lowest cost they've found yet. If so, it is stored as the new minimum.
In either case, they flip some elements of the matrix and try again. If the same matrix is the lowest for $2nm$ iterations, they consider it the global minimum. I don't think this is the most efficient way to find the minimum, and there's no guarantee that they will find the global minimum. This method is inherently random, so it doesn't need the usual randomness that a hill climbing algorithm needs.
With this information, they compute two important values: the mutual information shared by the two parties, and the size of lexicon. The size of the lexicon is defined as the number of symbols that refer to at least one reference object. What happens when you plot mutual information and lexicon size as a function of $\lambda$?
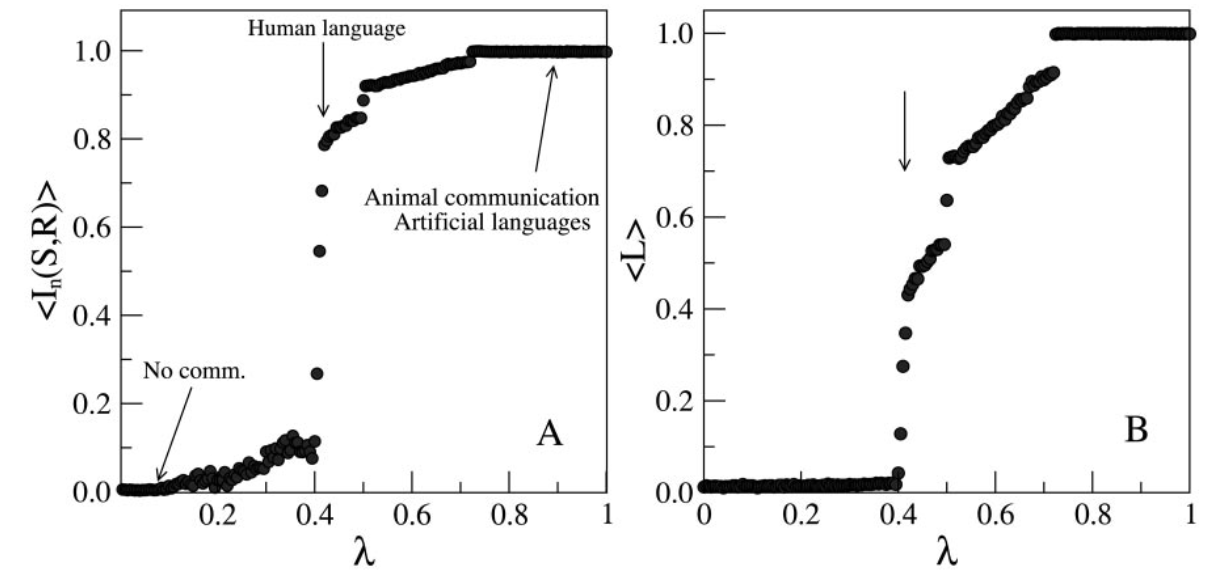
There is a sharp transition at $\lambda^* = 0.41$ around which resembles a Zipf distribution. $\lambda^*$ means that this is the value of $\lambda$ that minimizes $\Omega(\lambda)$.
So, it seems that human language resembles a cost function where the speaker bears slightly more of the cost than the listener. Further, it seems that Zipf's law follows naturally from a compromise on effort level by speakers and hearers.
But what of the other two extremes? If $\lambda$ were to decrease, mutual information decreases along with lexicon size. This means that the speaker must use fewer unique words that have more meanings. This increases the work for the hearer, who must decode from contextual information what each word means. I imagine African talking drums are the logical extreme of this idea.
If $\lambda$ were to increase, however, notice that the mutual information and lexicon size increase. This means that contextual information decreases as the message itself contains more and more information and less and less redundant hints. Each symbol has fewer synonyms. Imagine a program where across millions of lines of code, each variable name had to be unique. Frightening and wasteful.
Conclusions
What can we take away from this article? Zipf's law is not some random manifestation of language or communication but an arbitration between communicating parties. It lands at a logical conclusion of compromise that is amenable to programmers: writers do more work than readers but not so much that the lexicon grows to an untenable size and contextual information is kept at a reasonable level.
I found another article that I thought would be relevant, "The Emergence of Zipf's Law: Spontaneous Encoding Optimization by Users of a Command Language," by Steven R. Ellis and Robert J. Hitchcock4. It discusses plotting the length of Unix commands and their frequency with the hypothesis that the more expert the user the more closely their usage follows Zipf's Law.
This paper has a few issues, not the least of which is their lack of statistical documentation and extremely small sample size of only ten users. I do not think it is worth the cost IEEE asks for. However, they had some interesting recommendations: design your language to make the most often used things easy to use, and allow both new and experienced users an optimal experience.
How do you do both? You need to make a trade-off between ambiguity and cost. But always pay attention to the frequency of use. If it's more frequently used, it deserves a short, efficient name.
The variable name currentImageWidth might be just fine if you use it only twice, but if you use it two dozen times in a short time frame: make it short.
Make it follow Zipf's law.
Examples
The most frequently used word in this article was "the" with 193 mentions, followed by "of" with 105 and then "a" with 89. Interestingly, the word "Zipf" makes the top ten with 35 mentions.
But how can you check what you use in your source code? Well I nabbed this snippet and modified it slightly to work better with programs thusly:
tr -c '[:alnum:]' '[\n*]' < test.c | egrep '^[[:alpha:]]' | sort | uniq -c | sort -nr | head -12 | nl
This will output a list like this (from my project LiveStats):
1 89 self 2 37 i 3 21 x 4 18 tiles 5 17 heights 6 17 for 7 16 in 8 16 d 9 16 count 10 15 median 11 15 item 12 15 def
This includes a python keyword, for, which should be excluded. We can plot this via this small gnuplot snippet to generate this graph:

This plot is the same log-log style plot we saw earlier, but of the data in my program. It seems to have a Zipf-like distribution in its frequency. The exponent is near -1, which would be appropriate.
Try it out on your programs and see what you get.
-
I realize the apparent contradiction here in writing such a lengthy post and complaining about lengthy variables names. ↩
-
If you're interested in learning more about information theory and the history thereof, I recommend The Information by James Gleick. It's a really fun read with lots of interesting tidbits and histories. ↩
-
i Cancho, Ramon Ferrer, and Ricard V. Solé. "Least effort and the origins of scaling in human language." Proceedings of the National Academy of Sciences 100.3 (2003): 788-791. ↩
-
Ellis, S.R.; Hitchcock, Robert J., "The Emergence of Zipf's Law: Spontaneous Encoding Optimization by Users of a Command Language," Systems, Man and Cybernetics, IEEE Transactions on , vol.16, no.3, pp.423,427, May 1986 ↩